
게시글 교묘히 재가공 ‘저작권 침해’
경험 가장한 허위 정보 확산 우려도
플랫폼 측 “기술적으로 판별 어려워”
경험 가장한 허위 정보 확산 우려도
플랫폼 측 “기술적으로 판별 어려워”
10년 넘게 블로그를 운영해온 40대 홍모씨는 최근 온라인상에서 자신의 운동 후기와 유사한 게시글을 발견했다. 자신의 닉네임과 자신만이 알아볼 수 있는 운동 습관을 그대로 베낀 듯한 내용도 포함됐다. 홍씨는 인공지능(AI) 특유의 부자연스러운 문장으로 된 글이 7건이나 있는 것을 보고 도용을 확신했다. 곧바로 해당 플랫폼 권리보호센터에 신고했지만, ‘전체적인 내용은 달라 침해로 보기 어렵다’는 반려 통보를 받았다. 홍씨는 7일 “AI로 한 번 비틀기만 하면 도용이 아니게 되는 거냐”고 말했다.
AI 기술 발달로 블로그 게시글을 도용해 재가공한 콘텐츠가 무분별하게 확산하고 있다. 돈벌이 목적 등으로 원저작자의 콘텐츠를 그대로 베끼지만, 표현을 교묘히 바꾸는 식으로 저작권 침해 책임을 빠져나가기 때문에 피해 구제를 받지 못하는 사례가 많다.
온라인상에는 ‘도용에 안 걸리려고 ‘원천징수’를 ‘원천즹수’로 바꿔놨더라’ ‘내 여행 후기를 이모티콘까지 재포스팅했더라’ 등의 피해 호소가 이어졌다. 특히 원문과 유사한 콘텐츠가 검색 상단에 먼저 노출되는 역전 현상까지 벌어지고 있다.
AI를 활용해 양산형 콘텐츠를 쏟아내는 블로그는 짧은 시간에 제작이 가능하다. 이 때문에 경험을 가장한 허위 정보가 확산할 우려도 크다. 예를 들어 화장품 사용법 상세설명을 다른 블로그에서 그대로 복사한 뒤 AI에 ‘친구 추천으로 사서 한 달간 써봤다는 후기를 만들어 달라’고 요청해서 가짜 콘텐츠를 만드는 방식이다.
플랫폼 측은 AI 활용 자체가 제재 사유는 아니라는 입장이다. 네이버 관계자는 “원작성자의 증거자료가 충분할 경우 게시중단 조치를 하고 있고, 저품질 탐지 알고리즘도 고도화하고 있다”며 “AI로 작성했는지를 기술적으로 판별하기 어려운 부분이 있다”고 설명했다.
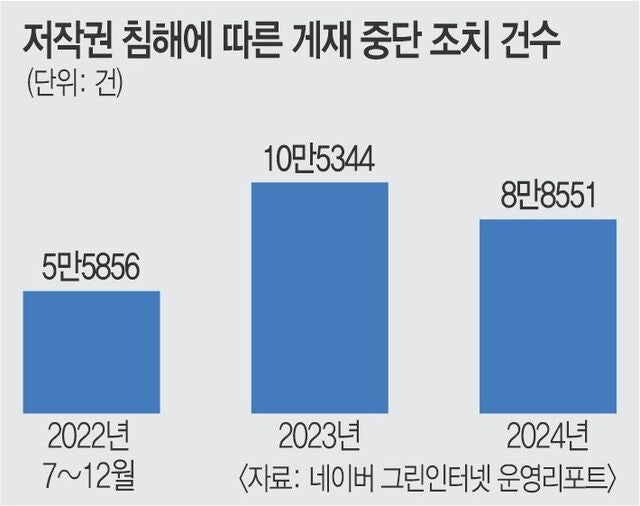
현재 네이버는 정보통신망법 및 저작권법에 따라 신고된 콘텐츠의 게시중단 여부를 결정하고 있다. 네이버가 공개한 저작권 침해에 따른 게재중단 조치는 2022년 하반기 기준 5만5856건, 2023년 10만5344건, 지난해 8만8551건에 달한다. 카카오도 유사한 운영정책을 따르지만, 두 플랫폼 모두 AI를 활용한 도용 건수는 별도로 공개하지 않고 있다.
콘텐츠 무단 도용 피해가 반복되자 블로그 운영자들은 ‘셀프 방어’ 노하우도 공유하고 있다. 워터마크 삽입, 텍스트 복사 방지 플러그인 설치, 정기 백업 등으로 스스로 원본을 보호하려는 움직임이 대표적이다.
성연식 동국대 컴퓨터AI학과 교수는 “AI 생성 글의 저작권에 대한 가이드라인 자체가 부족하다”며 “챗GPT 같은 대규모 언어모델은 온라인상 데이터를 대량 학습하는 경우도 많아 플랫폼이 조치를 취하기 어려운 측면도 있다”고 설명했다. 이어 “AI가 어떤 데이터를 참고했는지 출처를 명시하는 방식으로 신뢰성을 확보해야 한다”고 강조했다.